
마법과도 같이, 이 글을 읽고 난 여러분들은 다음과 같은 것들을 할 수 있게 됩니다.
• NoSQL 세계의 선봉장인 Cassandra 데이터베이스의 존재를 인지한다.
• Cassandra의 특징을 간략하게 이해한다.
• Cassandra를 간단하게 설치하고 기본 기능을 이용하는 방법을 안다.
Cassandra
NoSQL 세계에서 Cassandra의 위치는 절대적입니다. Voldemort, MongoDB, TokyoCabinet/Tyrant 등 쟁쟁한 NoSQL 제품군 중에서 왜Cassandra가 독보적인 위치를 점유하고 있는지 말씀드리고 싶습니다.
Cassandra는 원래 Facebook에서 만들었던 오픈소스 Distributed Database였습니다. 현재는 Apache 프로젝트로 자리를 옮겼습니다.
Cassandra의 가장 큰 장점은 ‘상대적으로 다른 NoSQL DB에 비하여 레퍼런스가 많고, 활발하게 개발되고 있다.’는 점입니다. 상당히 다양한 분야와 많은 기업에서 Cassandra를 사용하고 있으며, 2010년 아파치 Top-level project로 승격되었기 때문에 개발 과정이 매우 잘 관리되고 있다고 할 수있습니다.
Cassandra의 대표적인 활용 사례는 Facebook의 inbox search(페이스북 사용자 프로필 내부 검색)입니다. 여기서 사용하는 Cassandra클러스터 규모는 600개 이상의 CPU 코어와 120 테라바이트 이상의 용량을 포함하고 있습니다.[1] Twitter에서도 일부 서비스의 스토리지를 Cassandra로 전환하려는 움직임이 있으며[2], 소셜 뉴스 사이트인 Digg.com(Alexa.com 순위 98위)에서도 주요 서비스에 사용되고 있습니다.[3] 이 외에 텍스트 검색 오픈소스인 Lucene에 스토리지 부분을 Cassandra로 변환한 Lucandra도 만들어 지는 등[4] 여러 방면에서 사용된 경험이 많이 축적되어 있습니다.
특징
Cassandra는 구글에서 만든 BigTable[5]과 아마존에서 만든 Dynamo[6]의 특징을 합쳐서 생겨난 데이터베이스입니다. 구체적으로는BigTable의 특징인 Column-oriented model, memTable 그리고 SSTable 방식의 쓰기 방식을 채택하였고, Dynamo의 특징인 높은 가용성, 속도와 일관성 사이의 trade off 조절 기능을 도입하였습니다.[7]
Scalability
Scalability는 Cassandra의 가장 큰 특징입니다. 장비를 추가하고 제거하는 과정은 매우 단순합니다. 단지 새로운 장비를 추가하고 설정을 바꾼 후 Cassandra를 재시작하면 됩니다. Cassandra는 노드가 추가되면 자동적으로 Consistent hashing을 통해 각 노드가 가진 키의 개수를 맞춥니다.
Fault-Tolerant
Cassandra의 또 다른 특징은 single point of failure가 없다는 것입니다. 이 때문에 어떤 노드에 장애가 발생해도 전체 시스템은 멈추지 않습니다.
여러 노드가 한꺼번에 멈춰도 운 나쁘게 같은 데이터의 Replica가 모두 멈추는 것이 아니라면 read에는 문제가 없고, write는 replica에 관계없이 항상 가능합니다.
Consistency-Partition tolerance 사이의 균형
대부분의 NoSQL 데이터베이스들은 Availability와 Partition Tolerance를 달성하고, Consistency를 약하게 지원하는 방식을 채택했으나Cassandra는 Read replica count, write replica count를 설정하는 방식으로 Consistency와 Availability 사이의 균형을 사용자가 선택할 수 있도록 하였습니다. 설정하기에 따라 Consistency를 강화시켜 사용할 수도 있고, Availability를 강화시켜 사용할 수도 있습니다. 물론 두 가지 모두를 강화시키는 것은 불가능합니다.(CAP Theorem)
Column-oriented Data Model
Cassandra는 Column-oriented Data Model을 사용합니다.(Column-Oriented에 대한 설명은 'Database Technology for Large Scale Data’편에 자세히 나와 있습니다.)
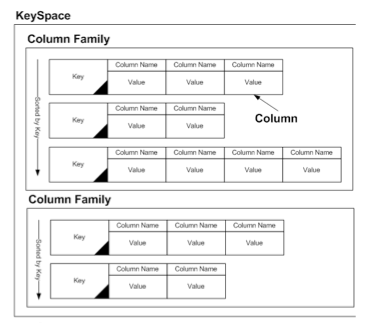
간단히 말해 RDBMS는 row를 레코드 형태로 저장하지만, Column-oriented Database에서는 Column을 모아 저장합니다. 당연히 연관된 데이터를 읽기에 적합합니다.
각 컬럼은 name, value, timestamp를 가지고 있습니다. Timestamp를 제외하면 각 Key에 Java의 HashMap, 또는 HashMap의HashMap 구조가 붙어있는 형태입니다.
아래 그림을 보면 이해가 빠를 것입니다.
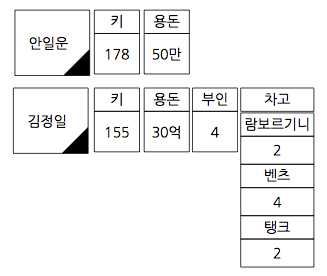
데이터의 key는 ‘안일운’, ‘김정일’이며, ‘안일운’ 키가 가진 컬럼들은 ‘키’, ‘용돈’이며 ‘김정일’ 키가 가진 컬럼들은 ‘키’, ‘용돈’, ‘부인’, ‘차고’입니다. 각 컬럼은 컬럼 제목(키, 용돈)과 컬럼 값(178, 50만원)을 가지고 있습니다.‘김정일’키에는 ‘안일운’키에는 없는 ‘부인’과 ‘차고’ 컬럼이 있습니다. ‘차고’ 컬럼은 여러 개의 하위 컬럼을 또 가질 수 있습니다. 컬럼을 여러 개 포함하는 컬럼은 SuperColumn이라고 합니다.
키 |
178 |
용돈 |
50만 |
|
15 |
용돈 |
30억 |
부인 |
4 |
차고 |
2 |
람보르기니 |
4 |
벤츠 |
2 |
탱크 |
실제로 Cassandra에서 Column-oriented Data Model을 다루다 보면 Keyspace, Column Family과 같은 용어부터 Cassandra 고유의 자료형(Type) 등 관계형 데이터베이스 세계에서 경험이 많았던 분들에게는 생소한 것들이 많이 등장합니다. 더 자세한 설명과 용어 해설은Cassandra 위키 페이지[8] 및 기타 웹사이트들[9,10,11]를 통해 읽으실 수 있습니다.
High Performance
Write
Cassandra는 Read 연산보다 Write연산이 훨씬 더 빠릅니다. 키의 위치에 따라 데이터 파일 중간 중간에 row를 끼워 넣는 방식이 아니라, SSTable(Sorted String Table)에 데이터를 Append한 후 SSTable을 통째로 저장하기 때문입니다. 데이터를 넣을 위치를 찾을 필요가 없어 일반적으로 관계형 데이터베이스보다 더 빠른 쓰기 속도를 보여줍니다.
Read
Write 연산으로 만들어진 SSTable은 일정 크기가 되면 key에 따라 정렬된 후 디스크에 기록됩니다. Read 연산 역시 기존 관계형 데이터베이스와는 달리, 각 SSTable의 bloom filter(어떤 데이터가 어떤 집합에 속해있는지 파악하기 위한 방법)를 통해 읽어올 데이터를 가지고 있는지 알아 낸 후 인덱스를 통해 정보를 읽어냅니다.
아직까지 공식적인 Read/Write 속도 테스트 결과는 없는 것으로 알고 있습니다. 다만 기존 관계형 데이터베이스(CUBRID, MySQL, Oracle등)와의 속도 직접 비교는 무의미할 수 있습니다. 데이터를 다루는 용도 및 목적 자체가 관계형 데이터베이스와 크게 다를 수 있기 때문입니다.
Lockless
Read/Write 연산 모두 lockless, 즉 한 스레드가 연산을 수행하는 동안 다른 스레드가 해당 데이터에 접근하지 못하는 경우가 없습니다. 동시성 문제(concurrency issue)로 인한 성능저하는 발생하지 않습니다.
제약사항
특징들을 나열해 놓고 보면 마치 개발자들이 원하고 원하던 꿈의 스토리지처럼 들리지만, 제약사항도 있습니다.
무엇보다 Cassandra는 1.0 버전이 아직 나오지 않은, 개발 중인 오픈 소스입니다. 상용화된 관계형 데이터베이스, 또는 MySQL같은 유구한 역사를 자랑하는 제품에 비해 기능 자체는 많이 부족한 상황입니다. 데이터를 Cassandra에 보관시켜놓고 운영 및 관리를 하다 보면MySQL의 편리한 도구들이 금방 그리워집니다. 버전 업 속도로 빠르고 기능추가, 기존 버전의 문제점 해결이 속속 이루어지고는 있으나 실제 서비스에 사용되는 코드의 일부가 되기에는 부족한 점이 많습니다. Cassandra를 활용하는 기업들도 주력이 아닌 2선급 서비스에 적용하거나, 백엔드 인프라로 활용하는 경우가 대부분입니다.
하지만 이런 단점에도 불구하고, Cassandra가 NoSQL 데이터베이스 중 가장 많은 기능을 가지고 있고 유망한 오픈 소스임에는 이의를 제기할 수 없다고 생각합니다.
Cassandra 설치와 동작
Cassandra의 설치는 비교적 간단한 편입니다.
Cassandra 홈페이지(http://cassandra.apache.org)에서 바이너리 파일을 다운로드 받은 후 압축을 풀기만 하면 됩니다.
Cassandra를 구동시키기 전 설정파일을 고쳐야합니다.
시험적으로 서버 1대만을 사용할 경우, 기본 설정 파일을 그대로 써도 문제가 없습니다. 다만 Cassandra 데이터 파일과 로그파일이 들어갈 디렉토리가 존재하는지 확인하고, 없다면 만들어 줄 필요는 있습니다.설정파일인 conf/storage-conf.xml을 보면CommitLogDirectory(로그 파일이 들어갈 디렉토리를 지정) 항목과 DataFileDirectories(실제 데이터 파일이 들어갈 디렉토리를 지정) 항목을 적절히 수정해 주면 됩니다.
<CommitLogDirectory>
/home1/data/cassandra/commitLog
</CommitLogDirectory>
<DataFileDirectories>
<DataFileDirectory>
/home1/data/cassandra/dataFile
</DataFileDirectory>
</DataFileDirectories>
만약 서버 2대 이상을 사용하는 클러스터를 구성하고 싶다면, 각 서버에 Cassandra를 설치한 후 설정파일을 각각 고쳐주어야 할 필요가 있습니다. 클러스터 구성 시 추가적으로 고쳐주어야 할 설정은 시드 설정과 통신 설정입니다.
시드(Seed)는, Cassandra 클러스터에 새로 추가되는 노드가 들어올 때, 이 신입 노드에게 노드들이 연결된 링 구조를 가르쳐 주는 역할을 수행합니다. 설정파일의 Seeds 항목을 보면 이를 설정할 수 있습니다. 아래 예시에서는 krs1164.nhncorp.com 호스트를 가진 장비를 시드로 지정하였습니다. 여러 개를 지정할 수도 있습니다.
<Seeds>
<Seed>krs1164.nhncorp.com</Seed>
</Seeds>
또한 클러스터의 노드들이 서로 통신할 때 사용하는 Gossip(클러스터의 링 구조에 관한 정보를 주고 받는데 사용)과 Thrift(클러스터가 실제로 저장하는 데이터를 교환하는데 사용)의 IP 인터페이스를 설정해야 합니다. 이들은 각각 ListenAddress와 ThriftAddress 항목에서 지정할 수 있습니다.
아래 예시에서는 krs1164.nhncorp.com에서 다른 Cassandra 클러스터의 노드와 통신하기 위해 20007과 20008 포트를 사용하도록 해 놓았습니다.
<ListenAddress>
krs1164.nhncorp.com
</ListenAddress>
<StoragePort>20007</StoragePort>
<ThriftAddress>
krs1164.nhncorp.com
</ThriftAddress>
<ThriftPort>20008</ThriftPort>
설정이 끝났으면 클러스터 내 모든 노드에서 각각 /bin/cassandra를 실행하면 됩니다. 기동되는 시간은 그리 길지 않습니다.
모든 노드가 정상적으로 가동되고 나면 Cassandra 클러스터가 제대로 동작하고 있는지 확인해 봅니다. /bin/nodetool을 사용하면 운영에 필요한 정보들을 얻을 수 있습니다. 아래 예시에서는 이미 어느 정도 사용한 Cassandra 클러스터의 링 구조를 보여주고 있습니다.
여기서 설명한 것 외에도, 설정파일에서는 많은 것들을 변경 할 수 있습니다. Memtable(Cassandra에서 key에 해당하는 value(Row)에 대한 cache) 크기나 응답대기 시간 같은 내부 동작 설정부터 데이터 저장 구조까지 모두 설정하도록 되어 있으므로 필요에 따라 많은 수정을 거쳐야 합니다.
설치와 설정파일에 관련된 정보가 완벽하게 정리된 가이드 같은 것은 아직 없습니다. 최신 버전이 0.7.0 beta인 오픈 소스라 어쩔 수 없는 상황이라고도 보입니다만 체계적인 문서화가 미흡한 점은 분명 아쉬운 부분입니다. Cassandra 개발 웹페이지(http://cassandra.apache.org)의 위키, 메일링 리스트 등을 열심히 탐독하다 보면 다양한 설정과 운영 방법에 대한 정보를 더 얻을 수 있습니다.
API 사용
Cassandra는 클라이언트와의 통신을 위해 Thrift API를 제공합니다. Thrift는 Facebook에서 개발한 RPC이며 다양한 언어를 지원합니다. Thrift도 현재 아파치 인큐베이터를 통해 개발되고 있습니다.
Cassandra 소스코드를 다운로드 받아놓았다면 이 소스코드에 포함된 Cassandra 클라이언트 패키지와 Thrift를 이용하여 클라이언트 프로그램을 작성할 수 있습니다.
Cassandra의 기본 설정파일인 conf/storage-conf.xml을 보면 Keyspace1이라는 키스페이스(MySQL의 Database에 해당) 하위에Standard1이라는 Column Family(MySQL의 Table에 해당)가 이미 정의되어 있습니다.
이 키스페이스에 값을 쓰고, 읽어오는 자바 소스코드는 다음과 같습니다. [14]에서 발췌한 내용을 일부 수정하였습니다. 소스코드는 찬찬히 들여다보시면 어렵지않게 이해하실 수 있으실 것입니다.
자바 뿐 아니라 PHP, C++, Python 등에서도 Cassandra의 모든 기능을 사용할 수 있습니다. 다른 언어로 된 소스코드도 샘플코드 페이지(http://wiki.apache.org/cassandra/ThriftExamples )에서 찾아보실 수 있습니다.
package cassandra.clientest;
import java.io.UnsupportedEncodingException;
import java.util.Date;
import java.util.List;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.Column;
import org.apache.cassandra.thrift.ColumnOrSuperColumn;
import org.apache.cassandra.thrift.ColumnParent;
import org.apache.cassandra.thrift.ColumnPath;
import org.apache.cassandra.thrift.ConsistencyLevel;
import org.apache.cassandra.thrift.InvalidRequestException;
import org.apache.cassandra.thrift.NotFoundException;
import org.apache.cassandra.thrift.SlicePredicate;
import org.apache.cassandra.thrift.SliceRange;
import org.apache.cassandra.thrift.TimedOutException;
import org.apache.cassandra.thrift.UnavailableException;
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
public class Main {
public static final String UTF8 = "UTF8";
public static void main(String[] args) throws UnsupportedEncodingException,
InvalidRequestException, UnavailableException, TimedOutException,
TException, NotFoundException {
// 접속할 노드를 지정하여 소켓을 정의합니다.
// 접속할 호스트는 Cassandra 클러스터 중 어떤 것이 되어도 상관없습니다.
TTransport tr = new TSocket("krs1164.nhncorp.com", 20008);
TProtocol proto = new TBinaryProtocol(tr);
Cassandra.Client client = new Cassandra.Client(proto);
tr.open();
String keyspace = "Keyspace1";
String columnFamily = "Standard1";
String keyUserID = "1";
// insert data
long timestamp = System.currentTimeMillis();
ColumnPath colPathName = new ColumnPath(columnFamily);
colPathName.setColumn("fullName".getBytes(UTF8));
client.insert(keyspace, keyUserID, colPathName,
"Chris Goffinet".getBytes(UTF8), timestamp, ConsistencyLevel.ONE);
ColumnPath colPathAge = new ColumnPath(columnFamily);
colPathAge.setColumn("age".getBytes(UTF8));
client.insert(keyspace, keyUserID, colPathAge, "24".getBytes(UTF8),
timestamp, ConsistencyLevel.ONE);
// read single column
System.out.println("single column:");
Column col = client.get(keyspace, keyUserID, colPathName,
ConsistencyLevel.ONE).getColumn();
System.out.println("column name: " + new String(col.name, UTF8));
System.out.println("column value: " + new String(col.value, UTF8));
System.out.println("column timestamp: " + new Date(col.timestamp));
// read entire row
SlicePredicate predicate = new SlicePredicate();
SliceRange sliceRange = new SliceRange();
sliceRange.setStart(new byte[0]);
sliceRange.setFinish(new byte[0]);
predicate.setSlice_range(sliceRange);
System.out.println(" row:");
ColumnParent parent = new ColumnParent(columnFamily);
List<ColumnOrSuperColumn> results = client.get_slice(keyspace,
keyUserID, parent, predicate, ConsistencyLevel.ONE);
for (ColumnOrSuperColumn result : results) {
Column column = result.column;
System.out.println(new String(column.name, UTF8) + " -> "
+ new String(column.value, UTF8));
}
tr.close();
}
}
가만히 살펴보면 범용 프레임워크인 Thrift를 이용해 Cassandra 노드와 통신하는 것은 그리 깔끔하지 못하다는 느낌을 받을 수 있습니다.
뿐만 아니라 한 대의 노드가 아닌 클러스터를 상대로 데이터 입출력 작업을 하다 보면 어떤 노드가 사용불능일 때의 처리, Connection Pooling 등의 기능이 필요해 질 때가 많습니다.
이러한 필요에 의해 Cassandra 클러스터에 접근하는 Thrift API를 한번 더 포장해서 만든 Cassandra 클라이언트 API도 공개되어 있습니다. Cassandra 고수준 클라이언트 소개 페이지(http://wiki.apache.org/cassandra/ClientOptions)에서 찾아 볼 수 있으며, 자바용 클라이언트로는 Hector[15]와 Pelops[16]가 유명합니다. 개인적인 경험으로는 Pelops 쪽이 좀 더 깔끔한 클라이언트 코드를 만드는 데 도움이 되었으나, Cassandra 버전업에 의해 기능이 변경되거나 추가되는 것을 반영하는 속도는 Hector에 비해서 좀 느린 감도 있었습니다.
Reference
[1] http://www.facebook.com/note.php?note_id=24413138919
[2] http://nosql.mypopescu.com/post/407159447/cassandra-twitter-an-interview-with-ryan-king
[3] http://about.digg.com/node/564
[4] http://blog.sematext.com/2010/02/09/lucandra-a-cassandra-based-lucene-backend/
[7] Avinash Lakshman, Prashant Malik, “Cassandra – Adecentralized Structured Storage System”,http://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf
[8] http://wiki.apache.org/cassandra/DataModel
[9] http://arin.me/blog/wtf-is-a-supercolumn-cassandra-data-model
[10] http://www.sodeso.nl/?p=108
[11] http://www.sodeso.nl/?p=207
[12] http://github.com/rantav/hector
'DataBase > NoSQL' 카테고리의 다른 글
| 몽고디비 - 초간단 가이드 (0) | 2013.11.27 |
|---|---|
| Database Technology for Large Scale Data, 박기은 (0) | 2011.02.11 |
| Cassandra db 로컬설치 (0) | 2011.02.11 |
| Cassandra [출처] Cassandra - facebook|작성자 녹천 (0) | 2011.02.11 |
| 아파치 분산 데이타 베이스 Cassandra 소개 (0) | 2011.02.11 |
댓글